
One of the fantastic capabilities of the Large Language Models is their ability to choose (based on a predefined set of tool definitions) the appropriate tool and its required parameters out of freely flowing conversation text. With that, they can act as facilitators of workflow orchestration, where they would instruct applications to invoke specific tools, with specific set of arguments.
OpenAI announced the built-in capability called function calling in the summer of last year, and by now it is an integral part of working with and building applications on top of the GPT models. The functionality was later renamed in the API to “tools”, to better express their broad scope and nature.
Today I am starting a new multi-post Azure OpenAI blog series focusing specifically on the tool capabilities. We will build a client application with .NET, and explore tool integration from different angles - using the Azure OpenAI .NET SDK directly, using the Assistants SDK and finally leveraging various orchestration frameworks such as Semantic Kernel and AutoGen. In today’s part one, we are going to introduce the basic concepts behind tool calling.
Series overview 🔗
- Part 1 (this part): The Basics
- Part 2: Using the tools directly via the SDK
The basics of LLM tool calling 🔗
Let’s start by working through how the “tool selection” feature of the LLMs works. Despite the name, it does not mean that the model will invoke any pieces of code - after all the models can be thought of (mathematically speaking) as functions without any side effects - input comes in, and output comes out. However, if they are provided with a list of definitions of available application tools, they are able to use the user prompt to select the most appropriate tool invocation as part of their response.
At the moment, when using Azure OpenAI, the only tools that are supported are function calls and they are structurally described using an OpenAPI schema. Additionally to that, a natural language description is needed for each function and its parameters - this is necessary for the model to comprehend the function and be able to reason about it and correctly infer the argument values.
In the response, the model would generate a JSON instructing the application to invoke the given tool. If that is not possible, the model may engage in a further conversation with the user - for example to ask follow up questions or require the user to specify the parameters more explicitly.
A simple example (in pseudo code) could be:
User Prompt: "notify Filip that the work is done"
Tools:
[
{
"name": "send_message",
"description": "Sends a message to the a specific with any content"
"parameters": {
"type": "object",
"properties": {
"recipient": {
"type": "string"
},
"text": {
"type": "string"
}
},
"required": ["recipient", "text"]
}
}
]
In this case the LLM was told that user Filip should be notified, and that there is a function send_message that allows sending messages to users. The response from the LLM might be an empty completion (no text), but just the JSON instruction for the tool call which the model determined:
Tool Choices:
[
{
"name": "send_message",
"parameters": {
"recipient": "Filip",
"text": "Great news! The work has been completed."
}
}
]
Based on this response, the application can then invoke the send_message as specified by the LLM. In this simple example we only have one function available but it is of course possible to supply many of them as input, and let the model select the most appropriate one. It is equally possible, that the model selects several tool calls in the response, which are then all expected to be called.
The way system instructions are designed can significantly influence the model’s approach to selecting functions. It might lean towards making assumptions about some parameters, attempting to predict or infer missing information. Conversely, it could adopt a more cautious stance, necessitating a more explicit specification of arguments. Just like any prompt engineering work, there is a lot of trial-and-error involved, as different generations or classes of models may require different specificity of instructions related to tool selection.
Workflow orchestration wit tools 🔗
Let’s now consider a more sophisticated flow, where the LLM is put in control of a process for booking concert tickets. We can imagine a workflow with four actors:
- the UI, representing the application surface that the user interacts with, and where the user writes the prompts that will end up in the LLM, and where the user reads the responses
- the Orchestrator, which is the layer between the LLM and the UI, responsible for supplying and invoking tools. This could be part of the client application, or a backend service
- the LLM, sitting in the Azure OpenAI Service
- the API, against which the functions can be invoked. In our example this will be a hypothetical Concert API, which exposes the following functions (again, using pseudo-code):
- search(band, location) - to search for concerts
- book(id), where the id is the id of the search entry returned by the other API call - to book a ticket
The overall workflow integration may look as follows:
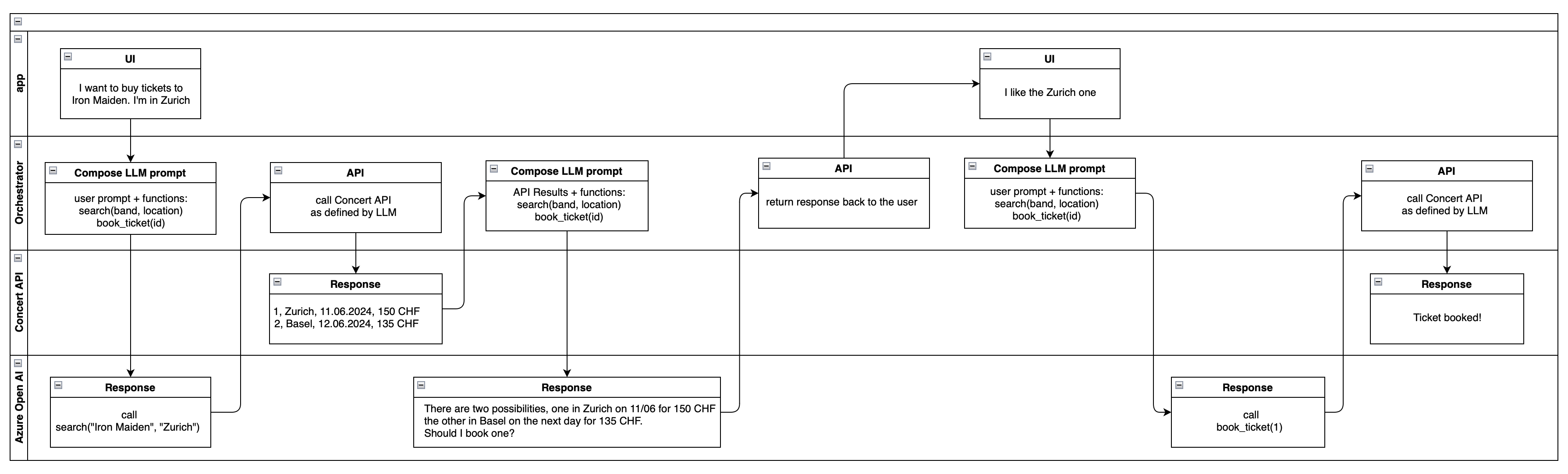
Let’s review quickly what is going on here.
First the user indicates (in natural language) that they would like to go to an Iron Maiden concert in Zürich. The orchestrator additionally injects the two Concert API functions (tools) to the request that will go to the Azure OpenAI model. The model then uses the user prompt to select the appropriate tool and fill in the parameters. Because the user provided sufficient information, this can actually be done successfully without any extra follow up questions.
The response from the model flows back to the orchestrator, which now realizes that the model selected a tool call. The orchestrator does that, and retrieves two matches - a concert in Zürich on 11/06/24 and in Basel on 12/06/2024 (presumably the Concert API does a fuzzy search on the location). The result of that API call (while this is not obvious on the diagram, one can assume the response would be in JSON or some other structured format, not natural language) is not returned directly to the user, but is instead sent back to the LLM running in Azure OpenAI. The available tools are still included.
The model then realizes that while the book_ticket(id) is there, it is not possible to infer which one to call - because both options 1 and 2 are equally valid. Instead, it “converts” the API call results into natural language and asks a follow up question “Should I book one?”. This is effectively the model asking for clarification over the value of the id parameter.
This response flows back to the user, how now indicates interest in the Zürich concert. The orchestrator forwards this prompt to the LLM, naturally still attaching the available system functions. At this point the model selects book_ticket(1), which is returned and the Orchestrator invokes to buy the ticket for the user, thus closing the workflow.
This is a workflow that is entirely doable, with minimal amount of work, with an LLM running in Azure OpenAI.
What’s next 🔗
In this post we have covered the introductory aspects of using tool calls with LLM to orchestrate workflows. This is one of the most powerful features of LLMs, allowing us to turn them into empowered agents, performing complex tasks on our behalf.
As outlined in the beginning of this post, in the next parts of this series we are going to look at writing the code that will demonstrate how tool calls can be incorporated into client applications in various ways.


