
On October 1st, OpenAI and Microsoft (Azure OpenAI) announced the availability of the GPT-4o Realtime API for speech and audio. It is a new, innovative way of interacting with the GPT-4o model family, the provides a “speech in, speech out” conversational interface. Contrary to traditional text-based APIs, the Realtime API allows sending the audio input directly to the model, and receiving the audio output back. This is a significant improvement over the existing solutions to voice-enabled assistants, which required converting the audio to text first, and then converting the text back to audio. The Realtime API is currently in preview, and the SDKs for various languages have mixed-level of support for them, but it is already possible to build exciting new applications with it.
The low-latency speech-based interface also poses some challenges to established AI architectural patterns, such as Retrieval-Augmented Generation (RAG) - and today we will tackle just that, and have a look at a small sample realtime-voice RAG app in .NET.
Retrieval-Augmented Generation with a realtime model 🔗
In the most basic RAG model, the orchestrator first retrieves the relevant information from the relevant data source, attaches it to the request sent to the model and then lets the model generate the response based on the retrieved grounding information. It all relies on the fact that it is easy to intercept the query from the user, and enrich the input that flows to the model with the relevant information.
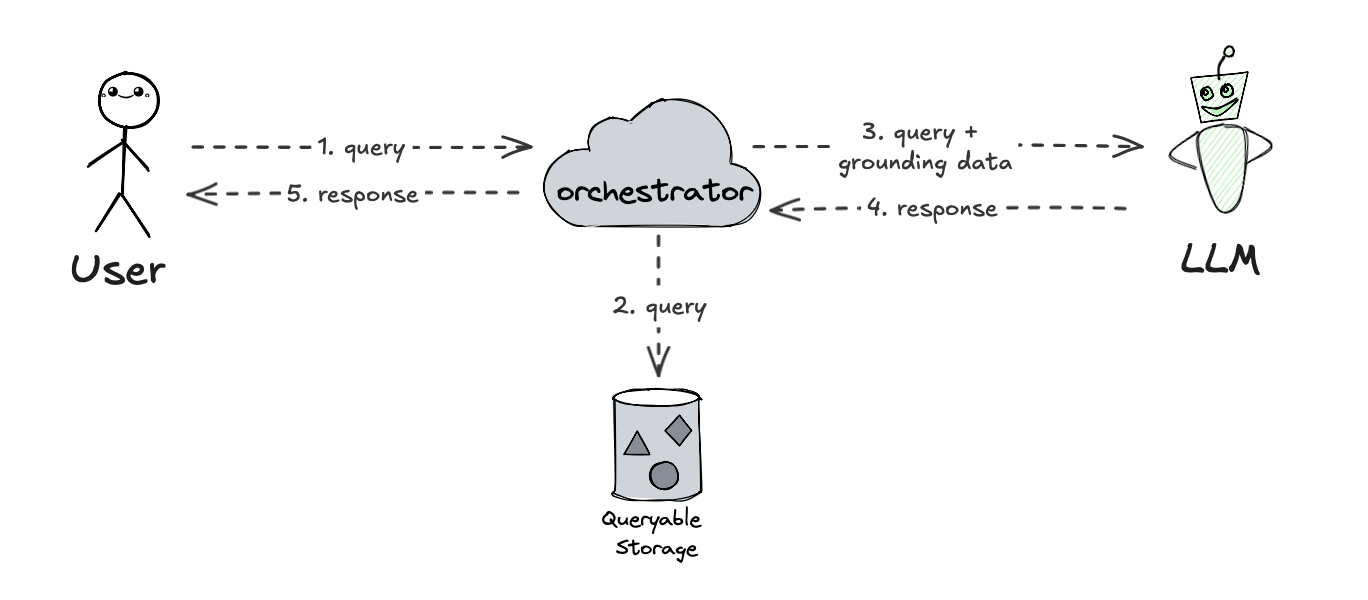
This is of course not the only embodiment of the RAG model, as it is quite oversimplified, and there are much more effective and sophisticated ways of doing it. The obvious candidate to improve this is to use embeddings, but this is orthogonal to the current discussion we have here, and they are intentionally omitted for simplicity.
But a more advanced variant of RAG could involve another LLM acting before the “main” LLM, and be responsible for determining the search query based on the user input and conversation history. This allows for a more dynamic and context-aware search query, and can significantly improve the quality of the generated responses. In such embodiment, the helper LLM can be supplied with a search tool definition, and it can also decide whether the search query should be executed at all.
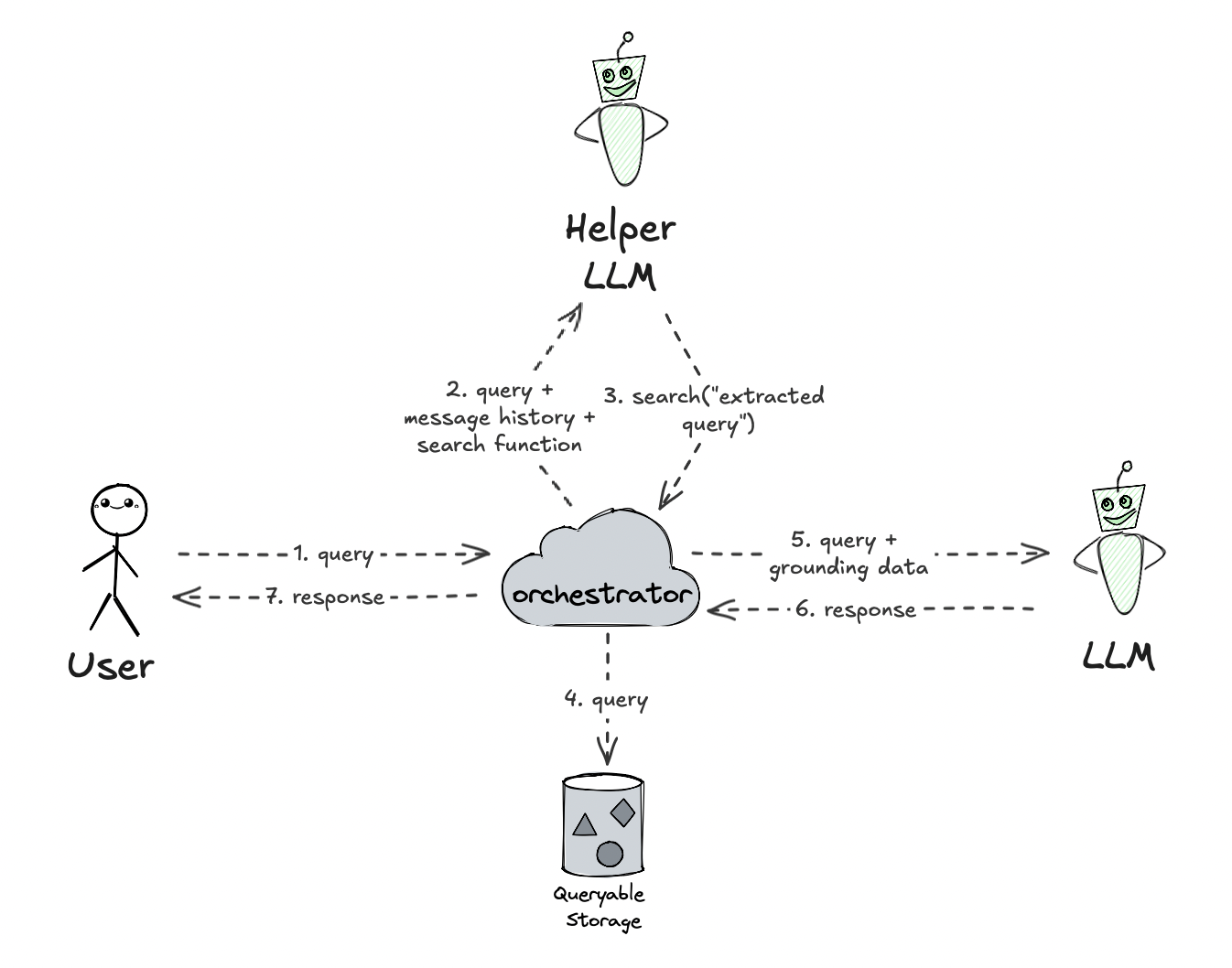
With a model capable of handling realtime user input, such as the GPT-4o with Realtime API, things become a lot more latency-sensitive, as the model can receive direct audio input from the user’s microphone - there exists a full-duplex communication between the user and the model. On top of this, it would be a lot more complicated for the orchestrator to try to intercept the input, decode the audio to determine the search query, and inject that into the communication protocol.
However, a simple pattern for an audio-enabled RAG could use the architecture we just defined above, and simply collapse the helper LLM and the assistant LLM together.
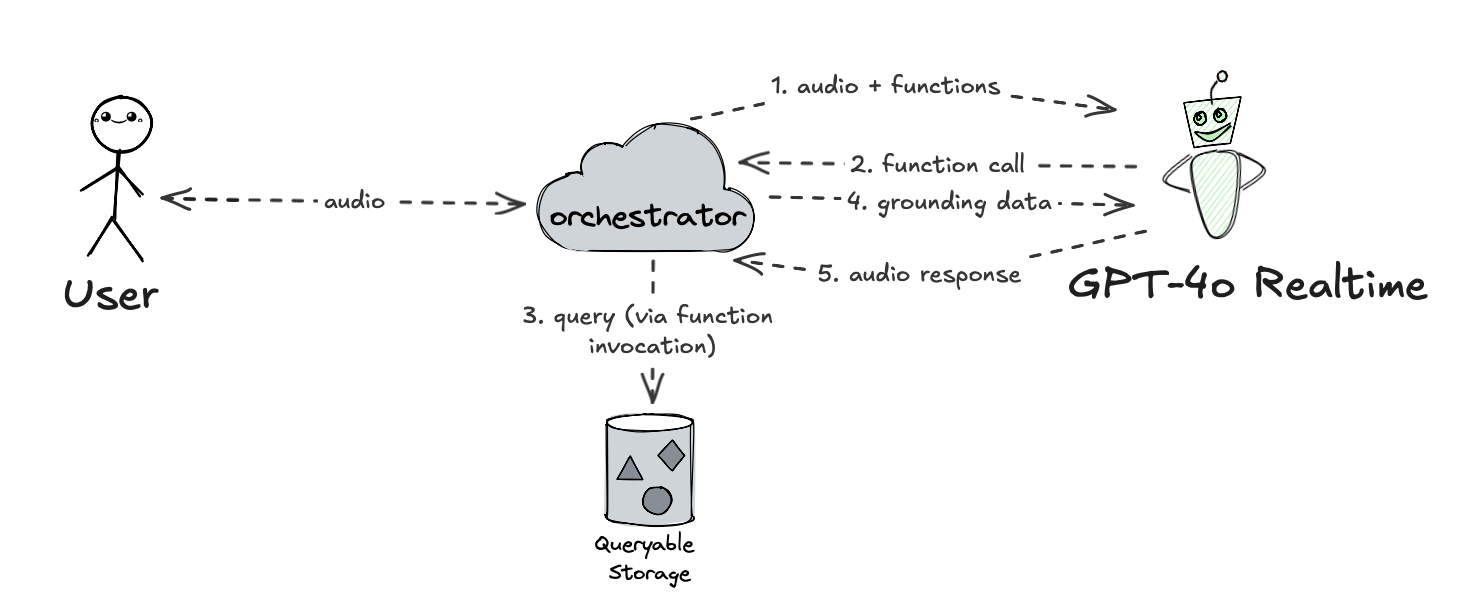
In this variant, the realtime model can determine if a further search is needed, and if so, it can choose to invoke the search tool. The orchestrator can then process the response from the model (before engaging the user), invoke the search tool, and then send the search results back to the model as pure text input. This way, we effectively skip a user’s turn, and the model can generate the audio response based on the retrieved information, which is then sent back to the user. The prerequisite for this to work is that the tool invocation is fast enough, because, again, we are in a latency critical environment.
Prerequisites 🔗
To be able to follow along with this tutorial, you will need to create an Azure OpenAI resource, GPT-4o Realtime Preview deployment and Azure AI Search resource.
Additionally, make sure the search is configured appropriately. You can import the index using the configuration file from the sample code for this article. Next, you need to index the data from the sample data folder into the new index. There are a few ways to do this, the simplest is to put the files in a blob storage, and then tell AI Search to index using JSON mode. The data set contains fake products from a sports store.
Finally, set the following environment variables:
AZURE_OPENAI_ENDPOINT=wss://<YOUR RESOURCE NAME>.openai.azure.com
AZURE_OPENAI_DEPLOYMENT=<YOUR DEPLOYMENT NAME>
AZURE_OPENAI_API_KEY=<YOUR AZURE OPENAI KEY>
AZURE_SEARCH_ENDPOINT=https://<YOUR AI SEARCH ACCOUNT>.windows.net
AZURE_SEARCH_INDEX=<YOUR SEARCH INDEX NAME>
AZURE_SEARCH_API_KEY=<YOUR AI SEARCH KEY>
Sample code 🔗
We are going to use .NET for this demo, as the latest beta Azure OpenAI client (version 2.1.0-beta.1) already supports the realtime API quite well. We will also need to reference Azure.Search.Documents package, to perform our RAG search.
Our project file looks as follows:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<OutputType>Exe</OutputType>
<TargetFramework>net9.0</TargetFramework>
<ImplicitUsings>enable</ImplicitUsings>
<NoWarn>OPENAI002</NoWarn>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Azure.AI.OpenAI" Version="2.1.0-beta.1" />
<PackageReference Include="Azure.Search.Documents" Version="11.6.0" />
<PackageReference Include="System.Text.Json" Version="8.0.5" />
</ItemGroup>
</Project>
OPENAI002 is a warning that should be muted because otherwise the compiler complains that we are using an experimental API.
Within our application, we will first bootstrap both the Azure OpenAI client, and the new RealtimeConversationClient:
var endpoint = Environment.GetEnvironmentVariable("AZURE_OPENAI_ENDPOINT") ??
throw new Exception("'AZURE_OPENAI_ENDPOINT' must be set");
var key = Environment.GetEnvironmentVariable("AZURE_OPENAI_API_KEY") ??
throw new Exception("'AZURE_OPENAI_ENDPOINT' must be set");
var deploymentName = Environment.GetEnvironmentVariable("AZURE_OPENAI_DEPLOYMENT") ?? "gpt-4o-realtime-preview";
var aoaiClient = new AzureOpenAIClient(new Uri(endpoint), new ApiKeyCredential(key));
var client = aoaiClient.GetRealtimeConversationClient(deploymentName);
as well as the search client:
var searchEndpoint = Environment.GetEnvironmentVariable("AZURE_SEARCH_ENDPOINT") ??
throw new Exception("'AZURE_SEARCH_ENDPOINT' must be set");
var searchCredential = Environment.GetEnvironmentVariable("AZURE_SEARCH_API_KEY") ??
throw new Exception("'AZURE_SEARCH_API_KEY' must be set");
var indexName = Environment.GetEnvironmentVariable("AZURE_SEARCH_INDEX");
var indexClient = new SearchIndexClient(new Uri(searchEndpoint), new AzureKeyCredential(searchCredential));
var searchClient = indexClient.GetSearchClient(indexName);
Next, we will prepare audio input, which will play the role of mic input in this demo.
For portability (.NET audio APIs and mic control are not cross-platform), the demo uses raw PCM audio files for input and output. The audio input comes from the sample audio file user-question.pcm (which is the user asking “do you have any flamingo products?”). The output is streamed back from the GPT-4o Realtime model as audio and saved into assistant-response.pcm.
var inputAudioPath = Path.Combine(Directory.GetCurrentDirectory(), "user-question.pcm");
await using var inputAudioStream = File.OpenRead(inputAudioPath);
In the next step, we will establish the audio session with the model. This is a place where we can provide system instructions, as well as attach the tools (functions) that are available to the model.
using var session = await client.StartConversationSessionAsync();
var sessionOptions = new ConversationSessionOptions()
{
Instructions =
"""
You are a helpful voice-enabled customer assistant for a sports store.
As the voice assistant, you answer questions very succinctly and friendly. Do not enumerate any items and be brief.
Only answer questions based on information available in the product search, accessible via the 'search' tool.
Always use the 'search' tool before answering a question about products.
If the 'search' tool does not yield any product results, respond that you are unable to answer the given question.
""",
Tools =
{
new ConversationFunctionTool
{
Name = "search",
Description = "Search the product catalog for product information",
Parameters = BinaryData.FromString(
"""
{
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "The search query e.g. 'miami themed products'"
}
},
"required": ["query"]
}
""")
}
},
InputAudioFormat = ConversationAudioFormat.Pcm16,
OutputAudioFormat = ConversationAudioFormat.Pcm16,
Temperature = 0.6f
};
await session.ConfigureSessionAsync(sessionOptions);
During this configuration, the model is informed about the availability of the search, which is a hook for us to do the RAG pattern. Afterwards, we dispatch audio input (remember, in this demo it pretends to be the mic input) to the model and starts processing responses.
await session.SendAudioAsync(inputAudioStream);
await Process(session);
The Process function processing the respons is shown next. The gist of it, is that the model can emit various types of responses (events), and we can choose which one we would like to react to.
The most obvious key one is ConversationAudioDeltaUpdate, which contains audio chunks to be pushed to the playback buffer. In our demo, we will collect them and save to the output file, but in a typical application, they could be streamed to the user’s speakers directly.
async Task Process(RealtimeConversationSession session)
{
var functionCalls = new Dictionary<string, StringBuilder>();
await using var outputAudioStream = File.Create("assistant-response.pcm");
await foreach (var update in session.ReceiveUpdatesAsync())
{
switch (update)
{
// collecting function arguments
case ConversationFunctionCallArgumentsDeltaUpdate argumentsDeltaUpdate:
if (!functionCalls.TryGetValue(argumentsDeltaUpdate.CallId, out StringBuilder value))
{
value = new StringBuilder();
functionCalls[argumentsDeltaUpdate.CallId] = value;
}
value.Append(argumentsDeltaUpdate.Delta);
break;
// collecting audio chunks for playback
case ConversationAudioDeltaUpdate audioDeltaUpdate:
outputAudioStream.Write(audioDeltaUpdate.Delta?.ToArray() ?? []);
break;
// collecting assistant response transcript to display in console
case ConversationOutputTranscriptionDeltaUpdate outputTranscriptDeltaUpdate:
Console.Write(outputTranscriptDeltaUpdate.Delta);
break;
// indicates assistant item streaming finished
case ConversationItemFinishedUpdate itemFinishedUpdate:
{
// if we have function call, we should invoke it and send back to the session
if (itemFinishedUpdate.FunctionCallId is not null &&
functionCalls.TryGetValue(itemFinishedUpdate.FunctionCallId, out var functionCallArgs))
{
var arguments = functionCallArgs.ToString();
Console.WriteLine($" -> Invoking: {itemFinishedUpdate.FunctionName}({arguments})");
var functionResult = await InvokeFunction(itemFinishedUpdate.FunctionName, arguments);
functionCalls[itemFinishedUpdate.FunctionCallId] = new StringBuilder();
if (functionResult != "")
{
var functionOutputItem =
ConversationItem.CreateFunctionCallOutput(callId: itemFinishedUpdate.FunctionCallId,
output: functionResult);
await session.AddItemAsync(functionOutputItem);
}
}
break;
}
// assistant turn ended
case ConversationResponseFinishedUpdate turnFinishedUpdate:
// if we invoked a function, we skip the user turn
if (turnFinishedUpdate.CreatedItems.Any(item => item.FunctionCallId is not null))
{
Console.WriteLine($" -> Short circuit the client turn due to function invocation");
await session.StartResponseTurnAsync();
}
else
{
return;
}
break;
case ConversationErrorUpdate conversationErrorUpdate:
Console.Error.WriteLine($"Error! {conversationErrorUpdate.ErrorMessage}");
return;
}
}
}
For the RAG process, we have to handle a few other update types. ConversationFunctionCallArgumentsDeltaUpdate will allow us to accumulate any information about the necessary function calls - we will buffer them until they are needed. ConversationItemFinishedUpdate will be raised once all the data related to a function call is collected, and at this stage we can invoke the function and send the results back to the model. The code does it by calling InvokeFunction method, which is not shown here, and we will return to it later.
Once the function result is available, we can attach it to a session using AddItemAsync. Once the model’s turn ends, ConversationResponseFinishedUpdate is sent. If we invoked a function - and this is the entire trick of this RAG approach here - we can skip the user’s turn, and start another turn of the assistant immediately. At this point the assistant can generate the response based on the retrieved data.
An additional thing that we handle is ConversationOutputTranscriptionDeltaUpdate, as that allows us to display the assistant’s response transcript in the console for debug purposes.
Since our original audio input was an audio file, we will not do further user turns, and we can exit the application after the first assistant response - this is fine for demo purposes.
The final missing piece is to add the InvokeFunction method, which will handle the search tool invocation. This is a simple method that will parse the function arguments, and based on the function name, will decide what to do. In our case, we only support the search tool, and we will invoke the search client with the query provided in the arguments.
async Task<string> InvokeFunction(string functionName, string functionArguments)
{
if (functionName == "search")
{
var doc = JsonDocument.Parse(functionArguments);
var root = doc.RootElement;
var query = root.GetProperty("query").GetString();
var result = await InvokeSearch(query, searchClient);
return result;
}
throw new Exception($"Unsupported tool '{functionName}'");
}
The search operation goes to Azure AI Search and performs a basic keyword search. The results are then collected and returned as the result. Obviously this step could be enhanced further, for example by introducing embeddings support (either directly in the code, or indirectly by using the Azure AI Search capabilities).
static async Task<string> InvokeSearch(string query, SearchClient searchClient)
{
SearchResults<Product> response = await searchClient.SearchAsync<Product>(query, new SearchOptions
{
Size = 5
});
var results = new StringBuilder();
var resultCount = 0;
await foreach (var result in response.GetResultsAsync())
{
resultCount++;
results.AppendLine($"Product: {result.Document.Name}, Description: {result.Document.Description}");
}
results.AppendLine($"Total results: {resultCount}");
var documentation = results.ToString();
Console.WriteLine($" -> Retrieved documentation:\n{documentation}");
return documentation;
}
public record Product(
[property: JsonPropertyName("description")]string Description,
[property: JsonPropertyName("name")] string Name);
With this in place, we can run the application. The console output should be something like:
-> Invoking: search({“query”:“flamingo”})
-> Retrieved documentation:
Product: Tropical Flamingo Basketball Gear, Description: The Tropical Flamingo Basketball Gear brings a bold and vibrant look to the court, featuring a striking flamingo and tropical foliage design. This kit is crafted for comfort and breathability, ensuring players stay cool and agile during games while making a standout style statement. Perfect for those who want to combine performance with a touch of tropical flair.
Product: Flamingo Pattern Football, Description: The Flamingo Pattern Football offers a unique and stylish twist with its vibrant flamingo design, perfect for players looking to bring some flair to the field. Built for durability and performance, this football combines functionality with eye-catching aesthetics, making it great for both practice and casual play. Ideal for those who want to stand out.
Product: Pink Flamingo Football Kit, Description: The Pink Flamingo Football Kit combines bold style with high-performance functionality, featuring a vibrant flamingo design that brings a fresh twist to the field. Engineered for comfort and durability, this kit ensures players can perform their best while standing out with a striking look. Perfect for athletes who want to add a unique flair to their game day gear.
Total results: 3
-> Short circuit the client turn due to function invocation
We have several flamingo-themed products, including the Tropical Flamingo Basketball Gear, the Flamingo Pattern Football, and the Pink Flamingo Football Kit. Each of these items features vibrant flamingo designs for a unique and stylish look.
The sample audio question is:
And the model response is going to be something like:
This is exactly what we expected, as these are the products in our dataset.
Conclusion 🔗
We have built a simple prototype of a realtime-voice RAG application using the GPT-4o Realtime API and Azure AI Search. The application demonstrates the basic principles of how to build a audio-enabled RAG application. The application can be further extended by adding more sophisticated search capabilities, such as embeddings, and by integrating into device audio APIs. The source code for this blog article can be found, as usually, on Github.
For further reading, I recommend Pablo Castro’s blog post on Microsoft Techcommunity, where he describes an approach for VoiceRAG in a client-server architecture. The sample Python/JS code for that article is also available on Github.
Finally, I recommend poking around the official Azure OpenAI Realtime Audio SDK repo. This blog post was partially inspired by the code samples from that repo.


