
Recently, I dedicated quite a lot of room on this blog to the topic of running Phi locally with the Strathweb Phi Engine. This time, I want to focus on a different aspect of adopting small language models like Phi - fine-tuning them. We are going to do this with Apple’s MLX library, which offers excellent performance for ML-related tasks on Apple Silicon.
We are going to do LoRA fine tuning of a Phi model, and then invoke it using Strathweb Phi Engine.
Prerequisites and the task 🔗
For the demo, we will transform Phi-3 (which was not trained to understand function calling!) to become a music library controller, capable of invoking the following functions:
- play_song(title)
- play_playlist(title)
- pause
- stop
- next track
- previous track
- volume up
- volume down
- mute
- unmute
The problem can be illustrated as:
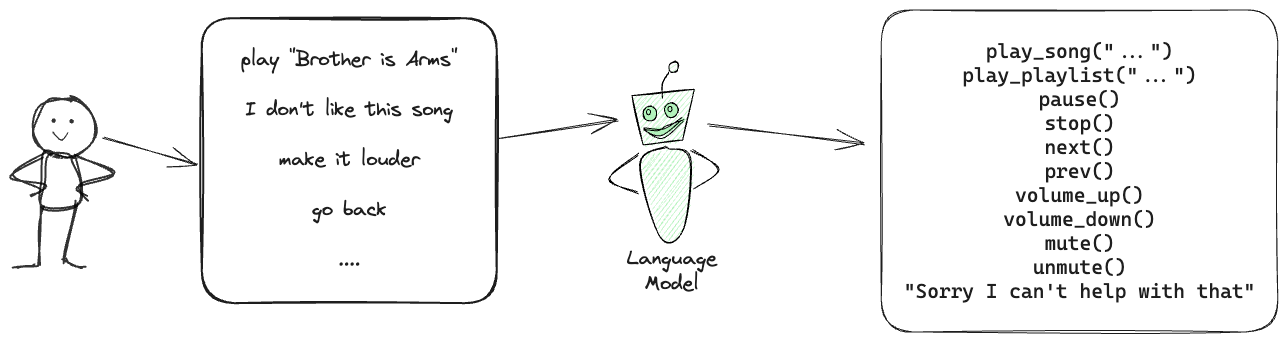
Note that this tutorial will only work on devices with Apple Silicon, as MLX only supports this class of hardware. At the same time, I am writing this on M1 Macbook Air, which is already over 4 years old, and is the weakest of the Apple Silicon devices, and yet the task still performs great - so you should be able to run this on any modern Apple laptop.
Fine tuning a model like Phi-3 for a task like this is a great way to leverage the power of small language models for a specific use case. It allows you to create a model that is more accurate and faster than the base model, and can be used in a variety of applications, as well as be deployed to edge devices.
Let’s start by installing MLX:
pip install mlx-lm
Preparation 🔗
Fine tuning will create an adapter that can be used to invoke the model with the new capabilities. The adapter can the be fused into the base model, effectively creating a new model that can be distributed and used for inference.
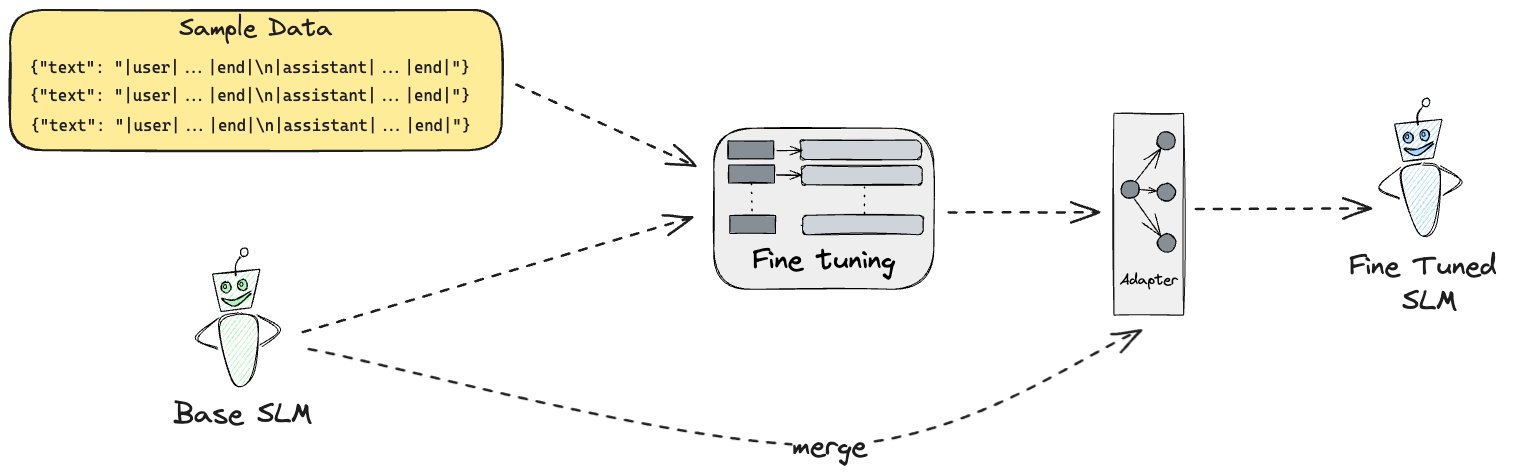
In order to get going, we need to prepare the training data, consisting of user inputs and the expected system outputs. We will use a simple JSONL format for this.
Sample extract from ./data/train.jsonl:
{"text": "<|user|>Play Bohemian Rhapsody<|end|>\n<|assistant|>fn:play_song \"bohemian rhapsody\"<|end|>"}
{"text": "<|user|>Start my workout playlist<|end|>\n<|assistant|>fn:play_list \"workout mix\"<|end|>"}
{"text": "<|user|>Next song<|end|>\n<|assistant|>fn:next<|end|>"}
{"text": "<|user|>Skip track<|end|>\n<|assistant|>fn:next<|end|>"}
{"text": "<|user|>Make it louder<|end|>\n<|assistant|>fn:vol_up<|end|>"}
{"text": "<|user|>Turn down volume<|end|>\n<|assistant|>fn:vol_down<|end|>"}
You can find a more extensive data set in the ./data folder of the accompanying source code. Typically a few hundred examples are enough to fine tune a model like Phi-3. We also need a separate validation set, which we will use to test the fine tuned model - it is important that this is a data set that the model has not seen before and that would not be used in fine tuning.
Next, we can run LoRa fine tuning using the MLX module, and point it at microsoft/Phi-3-mini-4k-instruct as our base model. MLX is capable of fetching base models from HuggingFace on its own. We will try with 500 iterations first, and use the LoRA defaults.
python -m mlx_lm.lora --model microsoft/Phi-3-mini-4k-instruct --train --data ./data --iters 500
With the included data set this runs about 10 min on my M1 Mac. It will be longer if each sample line is extended for more tokens.
Expected output should be similar too:
python -m mlx_lm.lora --model microsoft/Phi-3-mini-4k-instruct --train --data ./data --iters 500
Loading pretrained model
Fetching 13 files: 100%|███████████████████████████████████████████████| 13/13 [00:00<00:00, 120366.34it/s]
Loading datasets
Training
Trainable parameters: 0.082% (3.146M/3821.080M)
Starting training..., iters: 500
Iter 1: Val loss 5.617, Val took 10.292s
Iter 10: Train loss 5.889, Learning Rate 1.000e-05, It/sec 0.718, Tokens/sec 39.334, Trained Tokens 548, Peak mem 8.138 GB
Iter 20: Train loss 3.726, Learning Rate 1.000e-05, It/sec 0.963, Tokens/sec 62.197, Trained Tokens 1194, Peak mem 8.138 GB
Iter 30: Train loss 2.615, Learning Rate 1.000e-05, It/sec 0.907, Tokens/sec 61.238, Trained Tokens 1869, Peak mem 8.299 GB
Iter 40: Train loss 1.926, Learning Rate 1.000e-05, It/sec 0.215, Tokens/sec 12.482, Trained Tokens 2449, Peak mem 8.299 GB
Iter 50: Train loss 1.370, Learning Rate 1.000e-05, It/sec 1.062, Tokens/sec 63.596, Trained Tokens 3048, Peak mem 8.299 GB
Iter 60: Train loss 1.242, Learning Rate 1.000e-05, It/sec 0.765, Tokens/sec 52.368, Trained Tokens 3733, Peak mem 8.299 GB
Iter 70: Train loss 1.066, Learning Rate 1.000e-05, It/sec 0.912, Tokens/sec 64.395, Trained Tokens 4439, Peak mem 8.299 GB
Iter 80: Train loss 1.246, Learning Rate 1.000e-05, It/sec 1.130, Tokens/sec 63.478, Trained Tokens 5001, Peak mem 8.299 GB
Iter 90: Train loss 1.013, Learning Rate 1.000e-05, It/sec 1.129, Tokens/sec 70.541, Trained Tokens 5626, Peak mem 8.299 GB
Iter 100: Train loss 0.961, Learning Rate 1.000e-05, It/sec 1.069, Tokens/sec 64.164, Trained Tokens 6226, Peak mem 8.299 GB
Iter 100: Saved adapter weights to adapters/adapters.safetensors and adapters/0000100_adapters.safetensors.
Iter 110: Train loss 1.031, Learning Rate 1.000e-05, It/sec 1.043, Tokens/sec 60.923, Trained Tokens 6810, Peak mem 8.299 GB
... omitted for brevity ...
Iter 400: Train loss 0.770, Learning Rate 1.000e-05, It/sec 11.773, Tokens/sec 804.125, Trained Tokens 24728, Peak mem 8.311 GB
Iter 400: Saved adapter weights to adapters/adapters.safetensors and adapters/0000400_adapters.safetensors.
Iter 410: Train loss 0.787, Learning Rate 1.000e-05, It/sec 1.123, Tokens/sec 63.569, Trained Tokens 25294, Peak mem 8.311 GB
Iter 420: Train loss 0.795, Learning Rate 1.000e-05, It/sec 1.202, Tokens/sec 65.155, Trained Tokens 25836, Peak mem 8.311 GB
Iter 430: Train loss 0.841, Learning Rate 1.000e-05, It/sec 1.069, Tokens/sec 62.086, Trained Tokens 26417, Peak mem 8.311 GB
Iter 440: Train loss 0.776, Learning Rate 1.000e-05, It/sec 1.065, Tokens/sec 62.702, Trained Tokens 27006, Peak mem 8.311 GB
Iter 450: Train loss 0.843, Learning Rate 1.000e-05, It/sec 1.068, Tokens/sec 64.512, Trained Tokens 27610, Peak mem 8.311 GB
Iter 460: Train loss 0.799, Learning Rate 1.000e-05, It/sec 1.006, Tokens/sec 68.085, Trained Tokens 28287, Peak mem 8.311 GB
Iter 470: Train loss 0.825, Learning Rate 1.000e-05, It/sec 1.202, Tokens/sec 65.887, Trained Tokens 28835, Peak mem 8.311 GB
Iter 480: Train loss 0.749, Learning Rate 1.000e-05, It/sec 1.067, Tokens/sec 62.291, Trained Tokens 29419, Peak mem 8.311 GB
Iter 490: Train loss 0.707, Learning Rate 1.000e-05, It/sec 0.427, Tokens/sec 28.804, Trained Tokens 30093, Peak mem 8.311 GB
Iter 500: Val loss 0.845, Val took 10.376s
Iter 500: Train loss 0.705, Learning Rate 1.000e-05, It/sec 7.810, Tokens/sec 488.131, Trained Tokens 30718, Peak mem 8.311 GB
Iter 500: Saved adapter weights to adapters/adapters.safetensors and adapters/0000500_adapters.safetensors.
Saved final weights to adapters/adapters.safetensors.
Reviewing the results 🔗
Let’s consider what happened here. We first look at the loss progression:
- Starting val loss was 5.617, while final val loss reached 0.845
- Training loss stabilized around 0.7-0.8 in the later iterations
- Val loss has been fairly consistent since iter 200
The key observations that we can draw from this are:
- Very rapid initial improvement (loss dropped from 5.6 to ~1.0 in first 100 iterations), which stabilized well by iteration 200
- Small fluctuations but no concerning overfitting (val loss tracked training loss well)
- Final training loss around 0.7 is quite good for this type of task
Given these results, we can conclude that the model has trained (fine tuned) successfully, and that the 500 iterations was a good choice - we could have probably even stopped at 300-400 iterations.
The output is created into ./adapters folder and is an adapter which can be layered on top of the model.It should be about 140 MB in size.
Testing the adapter 🔗
The base model can now be invoked (via the mlx_lm.generate module) with the adapter, to test the fine tuning.
python -m mlx_lm.generate --model microsoft/Phi-3-mini-4k-instruct --adapter-path ./adapters --max-token 2048 --prompt "i don't like this song" --extra-eos-token "<|end|>" --temp 0.0
Expected output:
==========
fn:next
==========
Prompt: 10 tokens, 44.057 tokens-per-sec
Generation: 4 tokens, 9.403 tokens-per-sec
Peak memory: 7.821 GB
This seems promising - the model has correctly identified the user input and suggested the next track as the system output. The inference is also very fast, which is a good sign.
Validation 🔗
In order to check the outcome of the fine tuning, we can run a validation script that uses the data from ./data/valid.jsonl. This is a data set that the model has not seen before.
The script is shown below.
import json
import time
from mlx_lm import load, generate
from mlx_lm.sample_utils import make_sampler
from typing import List, Dict, Tuple
def load_validation_data(file_path: str, limit: int) -> List[Dict[str, str]]:
examples = []
print(f"Loading {limit} validation examples...")
with open(file_path, 'r') as f:
for i, line in enumerate(f):
if i >= limit:
break
data = json.loads(line.replace('*', '"'))
text = data["text"]
user_part = text.split('<|user|>')[1].split('<|end|>')[0]
assistant_part = text.split('<|assistant|>')[1].split('<|end|>')[0]
examples.append({
"input": user_part,
"expected": assistant_part
})
return examples
def run_inference(model, tokenizer, prompt: str, base_model: bool = False) -> Tuple[str, float]:
start_time = time.time()
if base_model:
system_prompt = """You control a music player. You can use these functions:
- play_song(title): Play a specific song
- play_list(title): Play a specific playlist
- pause: Pause playback
- stop: Stop playback
- next: Skip to next track
- prev: Go to previous track
- vol_up: Increase volume
- vol_down: Decrease volume
- mute: Mute audio
- unmute: Unmute audio
You should respond with a function call in the format: fn:function_name "parameter" (if needed and in lowercase)
For example: fn:play_song "bohemian rhapsody" or fn:play_list "workout mix" or fn:next. In all other cases you respond with "Sorry I cannot help with that"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt}
]
else:
messages = [{"role": "user", "content": prompt}]
sampler = make_sampler(0.0)
prompt = tokenizer.apply_chat_template(messages, add_generation_prompt=True)
response = generate(model, tokenizer, prompt=prompt, sampler=sampler, max_tokens=50)
if '<|assistant|>' in response:
response = response.split('<|assistant|>')[1]
if '<|end|>' in response:
response = response.split('<|end|>')[0]
return response.strip(), time.time() - start_time
def evaluate_model(model_path: str, adapter_path: str, validation_data: List[Dict[str, str]], model_name: str):
results = {"perfect": 0, "command": 0, "total": 0, "time": 0}
total_examples = len(validation_data)
index_width = len(str(total_examples))
print(f"\n=== Loading {model_name} ===")
model, tokenizer = load(model_path, adapter_path=adapter_path if adapter_path else None)
print(f"\n=== Testing {model_name} ===")
for i, example in enumerate(validation_data, 1):
input_text = example["input"]
expected = example["expected"]
actual, duration = run_inference(
model,
tokenizer,
input_text,
base_model=(adapter_path is None)
)
results["total"] += 1
perfect_match = expected.strip() == actual.strip()
results["perfect"] += int(perfect_match)
results["time"] += duration
print(f"[{i:{index_width}d}/{total_examples}] {'✓' if perfect_match else '✗'} '{input_text}' → {actual}")
print(f"\nSummary: {results['perfect']}/{total_examples} correct ({results['perfect'] / total_examples:.1%}), avg {results['time'] / total_examples:.1f}s per request")
del model
del tokenizer
return results
def main():
MODEL_PATH = "microsoft/Phi-3-mini-4k-instruct"
ADAPTER_PATH = "adapters"
VALIDATION_FILE = "data/valid.jsonl"
print("=== Starting Validation ===")
# we can set this to a larger value to test more examples
validation_data = load_validation_data(VALIDATION_FILE, limit=25)
finetuned_results = evaluate_model(MODEL_PATH, ADAPTER_PATH, validation_data, "Fine-tuned Model")
print("\n" + "="*50 + "\n")
base_results = evaluate_model(MODEL_PATH, None, validation_data, "Base Model")
if __name__ == "__main__":
main()
The script executes the inference against the fine tuned model (without the system instruction) and against the base model with a fairly complicated system instruction and a few shot learning approach. The result should show that the fine tuned model is not only faster than the base model (as it uses less tokens!) but also dramatically more accurate.
For demo purposes we restrict the validation set to 25 examples, but you can increase this number to get a better sense of the model’s performance.
python validate.py
The output should be similar to:
=== Starting Validation ===
Loading 25 validation examples...
=== Loading Fine-tuned Model ===
Fetching 13 files: 100%|██████████████████████████████████████████████████| 13/13 [00:00<00:00, 74387.38it/s]
=== Testing Fine-tuned Model ===
[ 1/25] ✓ 'Boost the volume' → fn:vol_up
[ 2/25] ✓ 'What's your name again?' → Sorry I cannot help with that
[ 3/25] ✓ 'Turn up' → fn:vol_up
[ 4/25] ✓ 'Lower it' → fn:vol_down
[ 5/25] ✓ 'Last song please' → fn:prev
[ 6/25] ✓ 'Skip' → fn:next
[ 7/25] ✓ 'Stop all' → fn:stop
[ 8/25] ✓ 'Audio enable' → fn:unmute
[ 9/25] ✓ 'start power workout' → fn:play_list "power workout"
[10/25] ✓ 'Play We Will Rock You' → fn:play_song "we will rock you"
[11/25] ✓ 'Play Any Way You Want It' → fn:play_song "any way you want it"
[12/25] ✓ 'Forward' → fn:next
[13/25] ✓ 'Play Faithfully' → fn:play_song "faithfully"
[14/25] ✓ 'Play Open Arms' → fn:play_song "open arms"
[15/25] ✓ 'Play Separate Ways' → fn:play_song "separate ways"
[16/25] ✓ 'Switch' → fn:next
[17/25] ✓ 'Back' → fn:prev
[18/25] ✓ 'Reverse' → fn:prev
[19/25] ✓ 'End' → fn:stop
[20/25] ✓ 'Finish it' → fn:stop
[21/25] ✓ 'Pause now' → fn:pause
[22/25] ✓ 'Stop briefly' → fn:pause
[23/25] ✓ 'Silent' → fn:mute
[24/25] ✓ 'No noise' → fn:mute
[25/25] ✓ 'Kill audio' → fn:stop
Summary: 25/25 correct (100.0%), avg 1.3s per request
==================================================
=== Loading Base Model ===
Fetching 13 files: 100%|██████████████████████████████████████████████████| 13/13 [00:00<00:00, 41401.63it/s]
=== Testing Base Model ===
[ 1/25] ✓ 'Boost the volume' → fn:vol_up
[ 2/25] ✗ 'What's your name again?' → I'm Phi, an AI developed by Microsoft.
[ 3/25] ✓ 'Turn up' → fn:vol_up
[ 4/25] ✓ 'Lower it' → fn:vol_down
[ 5/25] ✗ 'Last song please' → fn:next
[ 6/25] ✓ 'Skip' → fn:next
[ 7/25] ✓ 'Stop all' → fn:stop
[ 8/25] ✓ 'Audio enable' → fn:unmute
[ 9/25] ✓ 'start power workout' → fn:play_list "power workout"
[10/25] ✗ 'Play We Will Rock You' → fn:play_song "We Will Rock You"
[11/25] ✗ 'Play Any Way You Want It' → fn:play_song "Any Way You Want It"
[12/25] ✓ 'Forward' → fn:next
[13/25] ✗ 'Play Faithfully' → fn:play_song "Faithfully"
[14/25] ✗ 'Play Open Arms' → fn:play_song "Open Arms"
[15/25] ✗ 'Play Separate Ways' → fn:play_song "Separate Ways"
[16/25] ✓ 'Switch' → fn:next
[17/25] ✗ 'Back' → fn:play_song "Back in Black"
[18/25] ✓ 'Reverse' → fn:prev
[19/25] ✗ 'End' → fn:stop
fn:mute
fn:vol_down
[20/25] ✗ 'Finish it' → I'm sorry, but it seems like there was no specific request or command provided to respond to. If you have a command or request related to the music player functions, please provide it, and I'll respond accordingly.
[21/25] ✓ 'Pause now' → fn:pause
[22/25] ✗ 'Stop briefly' → fn:stop
[23/25] ✓ 'Silent' → fn:mute
[24/25] ✗ 'No noise' → fn:mute
This command will mute the audio output of the music player, effectively stopping any noise from being emitted.
[25/25] ✓ 'Kill audio' → fn:stop
Summary: 13/25 correct (52.0%), avg 2.5s per request
This gives us a nice idea of how a fine tuned model clearly outperforms the base model, despite our best effort to provide a decent system prompt. Additionally, we can see how the fine tuned model is not only more accurate but also 2x faster, because we use fewer tokens in the prompt, which is of course critical for edge devices and their constrained resources.
Merging the adapter into the model 🔗
When we are happy with the adapters’ behavior and performance, we can merge them into the base model. This is done using the mlx_lm.fuse module.
python -m mlx_lm.fuse --model microsoft/Phi-3-mini-4k-instruct
This creates a fused safe tensors model inside ./fused_model folder. From there it can be used directly with any ML framework that supports safe tensors, or it can be subject to quantization or other optimizations.
We can now load it into Strathweb Phi Engine and run inference with it. Remember, it supports a range of languages, but for this example I chose Swift:
import Foundation
let sourceFileDir = (#file as NSString).deletingLastPathComponent
// this assumes a certain structure followed by the source code repo
let basePath = ((sourceFileDir as NSString).appendingPathComponent("../../../../../fine-tuning/fused_model") as NSString).standardizingPath
let modelBuilder = PhiEngineBuilder()
_ = try modelBuilder.tryUseGpu()
try modelBuilder.withModelProvider(modelProvider: PhiModelProvider.fileSystem(
indexPath: "\(basePath)/model.safetensors.index.json",
configPath: "\(basePath)/config.json"
))
let model = try modelBuilder.build(cacheDir: (sourceFileDir as NSString).appending("/.cache"))
let context = ConversationContext(messages: [], systemInstruction: "")
let prompts = [
"Play alt rock",
"too loud",
"Skip this",
"Next one please",
"Change song",
"play Comfortably Numb",
"Go to lst song",
"What's the time?",
"pause it",
"make it quieter",
"What should I eat?",
"off",
"Start focus music",
"unmute",
"What's your favorite color?",
]
let inferenceOptionsBuilder = InferenceOptionsBuilder()
try inferenceOptionsBuilder.withTemperature(temperature: 0.0)
try inferenceOptionsBuilder.withTokenCount(contextWindow: 50)
let inferenceOptions = try inferenceOptionsBuilder.build()
for prompt in prompts {
let result = try model.runInference(promptText: prompt, conversationContext: context, inferenceOptions: inferenceOptions)
print("\(prompt) -> \(result.resultText)")
}
This will run the inference on the fine tuned model, and the output should be similar to:
Play alt rock -> fn:play_list "alt rock"
too loud -> fn:vol_down
Skip this -> fn:next
Next one please -> fn:next
Change song -> fn:next
play Comfortably Numb -> fn:play_song "comfortably numb"
Go to lst song -> fn:prev
What's the time? -> Sorry I cannot help with that
pause it -> fn:pause
make it quieter -> fn:vol_down
What should I eat? -> Sorry I cannot help with that
off -> fn:mute
Start focus music -> fn:play_list "focus"
unmute -> fn:unmute
What's your favorite color? -> Sorry I cannot help with that
Conclusions 🔗
In this post we went through end-to-end example of fine tuning a Phi-3 model with MLX, teaching the model to become a music system controller. We then validated the model against a set of unseen examples, and finally merged the adapter into the base model, and ran inference with it.
The source code is available on Github.


