
I recently blogged about building GPT-powered applications with Azure OpenAI Service. In that post, we looked at using the text-davinci-003 model to provide classification capabilities for natural text - more specifically, we categorized and rated scientific papers based on the interest area (note that the recommended model for this task now is gpt-35-turbo now).
In today’s post we are going to continue exploring Azure OpenAI Service, this time looking at the embeddings model, text-embedding-ada-002.
Embeddings 🔗
Embeddings are vectors of floating type numbers obtained from input strings. Once our texts have vector representations, by using vector operations, such as measuring distance or taking a dot product, we can easily obtain similarity between those text snippets. This, in turn, can then be used for a number of purposes, such as searching, clustering, anomaly detection or classification.
The latest OpenAI embedding model is text-embedding-ada-002, and it allows inputting a string of max length of 8191 tokens, and outputs a vector of 1536 dimensions. The 001 model is still there, but is considered legacy and should no longer be used.
Embeddings in Azure OpenAI Service 🔗
In the previous post I already covered the basics of getting started with Azure OpenAI Services, so we will not repeat that here. Have a look at that post to get started in case you do not have access to Azure OpenAI Services in your Azure subscription. If you already do, to get started with embeddings, we need to deploy the text-embedding-ada-002 model, which can be done from Azure OpenAI Studio, under the “Deployments” tab.
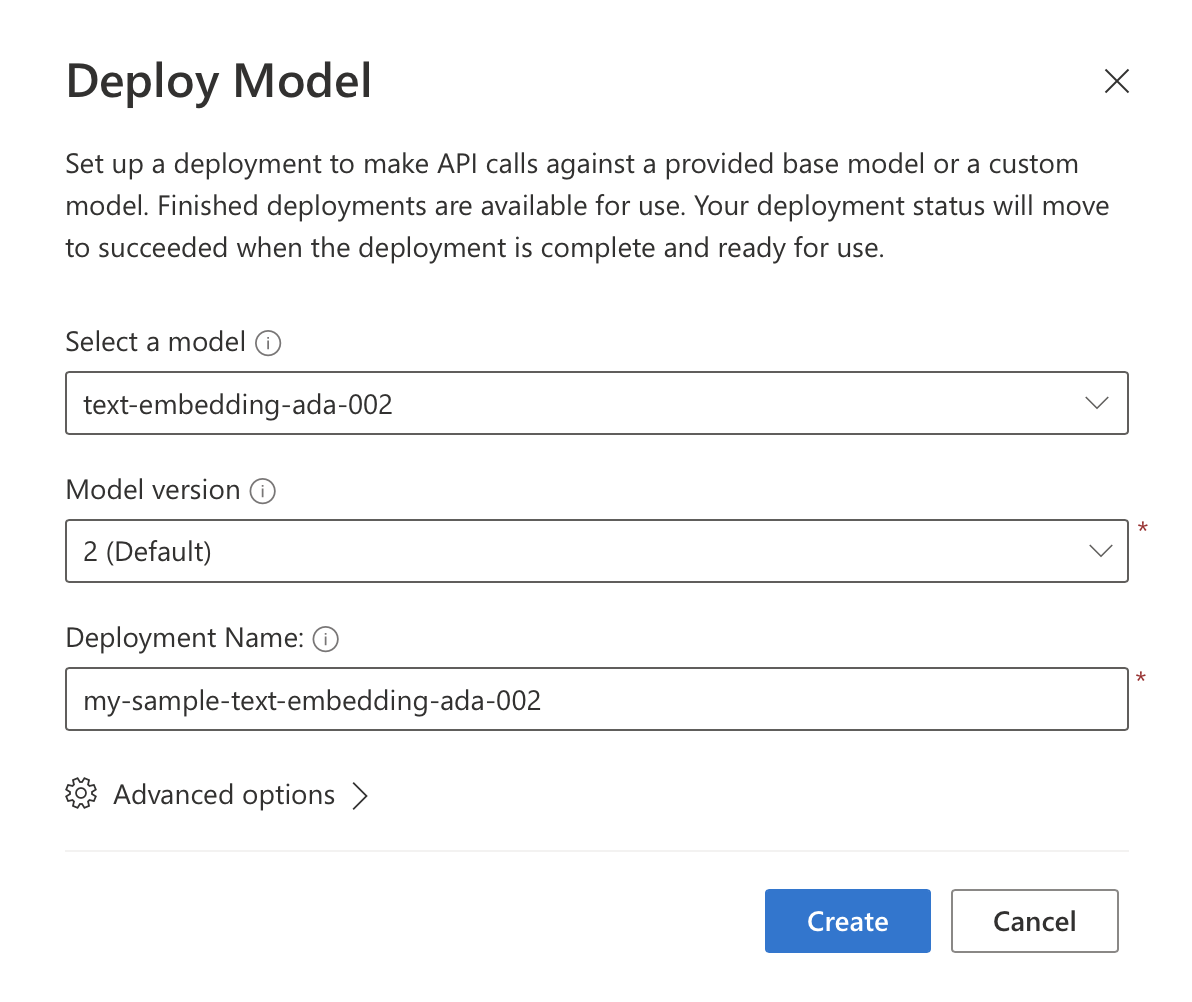
Building a sample app 🔗
Last time we built a small .NET application capable of fetching the given day’s quantum physics papers from Arxiv, and then we let our model rate them in terms of their relatedness to quantum computing.
In today’s post, we shall stay within that theme, which will allow us to reuse some of the code - in particular the infrastructure code around the core concepts we are focusing on. We will yet again fetch papers from Arxiv using their XML API, but this time we will use embeddings to help us generate recommendations for articles that could be interesting. We will use one paper’s title and it’s abstract, one that I particularly liked, as a baseline. We will then convert each retrieved article and its abstract to an embedding, and then we will compare that to the baseline (the “liked”) embedding - high similarity score would indicate a recommendation.
To get going, let’s extract the code that fetched papers from Arxiv for a given date into a function that could be freely called. We will not go through that code again (or the related DTO objects) because we already did that in the previous post, so it’s only shown below for the record. The data types can be found in the previous post or in the Github source code.
public static class ArxivHelper
{
public static async Task<Feed> FetchArticles(string searchQuery, string date, int maxResults = 40)
{
var feedUrl =
$"https://export.arxiv.org/api/query?search_query={searchQuery}+AND+submittedDate:[{date}0000+TO+{date}2359]&start=0&max_results={maxResults}&sortBy=submittedDate&sortOrder=descending";
var httpClient = new HttpClient();
var httpResponse = await httpClient.GetAsync(feedUrl);
Feed feed = null;
if (httpResponse.IsSuccessStatusCode)
{
var ns = XNamespace.Get("http://www.w3.org/2005/Atom");
var opensearch = XNamespace.Get("http://a9.com/-/spec/opensearch/1.1/");
var arxiv = XNamespace.Get("http://arxiv.org/schemas/atom");
var xmlContent = await httpResponse.Content.ReadAsStringAsync();
var xDoc = XDocument.Parse(xmlContent);
var feedElement = xDoc.Element(ns + "feed");
feed = new Feed
{
Title = (string)feedElement.Element(ns + "title"),
Id = (string)feedElement.Element(ns + "id"),
Updated = (DateTime)feedElement.Element(ns + "updated"),
TotalResults = (int)feedElement.Element(opensearch + "totalResults"),
StartIndex = (int)feedElement.Element(opensearch + "startIndex"),
ItemsPerPage = (int)feedElement.Element(opensearch + "itemsPerPage"),
Entries = feedElement.Elements(ns + "entry").Select(entryElement => new Entry
{
Id = ((string)entryElement.Element(ns + "id")).Split(".").Last()[..^2],
Updated = (DateTime)entryElement.Element(ns + "updated"),
Published = (DateTime)entryElement.Element(ns + "published"),
Title = (string)entryElement.Element(ns + "title"),
Summary = (string)entryElement.Element(ns + "summary"),
Authors = entryElement.Elements(ns + "author").Select(authorElement => new Author
{
Name = (string)authorElement.Element(ns + "name")
}).ToList(),
PdfLink = entryElement.Elements(ns + "link")
.FirstOrDefault(link => (string)link.Attribute("title") == "pdf")?.Attribute("href")?.Value,
PrimaryCategory =
(string)entryElement.Element(arxiv + "primary_category")?.Attribute("term")?.Value,
Categories = entryElement.Elements(ns + "category")
.Select(category => (string)category.Attribute("term")).ToList()
}).ToList()
};
}
return feed;
}
}
In order to start with our sample .NET console application, we need to install the Azure OpenAI NuGet package.
<ItemGroup>
<PackageReference Include="Azure.AI.OpenAI" Version="1.0.0-beta.7" />
</ItemGroup>
Next, our application will need the Azure OpenAI Service key, the model name and the URL of our service. This is no different from how we bootstrapped the app and interacted with the model last time. All of that information will come from your Azure subscription and would be specific to your environment. The code snippet below shows initializing the OpenAIClient client using that data, expecting that it would be coming from environment variables (to avoid committing them to source control).
The code also allows passing the data as program argument to query for ArXiv quantum physics articles from a specific date. This is the same concept that we used last time around. Finally, the actual Arxiv feed is retrieved.
var azureOpenAiServiceEndpoint = Environment.GetEnvironmentVariable("AZURE_OPENAI_SERVICE_ENDPOINT") ??
throw new ArgumentException("AZURE_OPENAI_SERVICE_ENDPOINT is mandatory");
var azureOpenAiServiceKey = Environment.GetEnvironmentVariable("AZURE_OPENAI_API_KEY") ??
throw new ArgumentException("AZURE_OPENAI_API_KEY is mandatory");
var azureOpenAiDeploymentName = Environment.GetEnvironmentVariable("AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME") ??
throw new ArgumentException("AZURE_OPENAI_EMBEDDING_DEPLOYMENT_NAME is mandatory");
var date = args.Length == 1 ? args[0] : DateTime.UtcNow.ToString("yyyyMMdd");
var feed = await ArxivHelper.FetchArticles("cat:quant-ph", date);
if (feed == null)
{
Console.WriteLine("Failed to load the feed.");
return;
}
var client = new OpenAIClient(new Uri(azureOpenAiServiceEndpoint), new AzureKeyCredential(azureOpenAiServiceKey));
In the next step, we will prepare our baseline embedding. There could be many ways of doing that, including letting the user rate different papers in terms of their interests, but for simplicity we will just use one hardcoded baseline as an example.
var baseline =
"""
Optimal Qubit Reuse for Near-Term Quantum Computers
Near-term quantum computations are limited by high error rates, the scarcity of qubits and low qubit connectivity.
Increasing support for mid-circuit measurements and qubit reset in near-term quantum computers enables qubit reuse that may yield quantum computations with fewer qubits and lower errors.
In this work, we introduce a formal model for qubit reuse optimization that delivers provably optimal solutions with respect to quantum circuit depth, number of qubits, or number of swap gates for the first time.
This is in contrast to related work where qubit reuse is used heuristically or optimally but without consideration of the mapping effort.
We further investigate reset errors on near-term quantum computers by performing reset error characterization experiments.
Using the hereby obtained reset error characterization and calibration data of a near-term quantum computer, we then determine a qubit assignment that is optimal with respect to a given cost function.
We define this cost function to include gate errors and decoherence as well as the individual reset error of each qubit.
We found the reset fidelity to be state-dependent and to range, depending on the reset qubit, from 67.5% to 100% in a near-term quantum computer.
We demonstrate the applicability of the developed method to a number of quantum circuits and show improvements in the number of qubits and swap gate insertions, estimated success probability, and Hellinger fidelity of the investigated quantum circuits.
""";
var baselineEmbedding = await client.GetEmbeddingsAsync(azureOpenAiDeploymentName,
new EmbeddingsOptions(baseline));
var baselineVector = likedEmbedding.Value.Data[0].Embedding.ToArray();
To get the embedding we use the OpenAIClient and invoke the GetEmbeddingsAsync method, passing in the string representation of the baseline paper as input. Notice the baseline is formatted as title - empty line - abstract. To stay consistent. we will use the same formatting pattern when generating other embeddings too.
At this point we have to iterate through all the papers retrieved from the Arxiv feed, and generate an embedding for each of them. As soon as we have a vector representation of a given paper, we can calculate similarity score to the baseline. Similarity can be calculated using a distance function - most typically it would be cosine similarity. For .NET we can use the implementation from the Microsoft.SemanticKernel NuGet package, which would have to be installed into our application.
<ItemGroup>
<PackageReference Include="Azure.AI.OpenAI" Version="1.0.0-beta.7" />
<PackageReference Include="Microsoft.SemanticKernel" Version="0.23.230906.2-preview" />
</ItemGroup>
As we loop through all the entries from the Arxiv feed, we will hold the results - the entry itself, the similarity score and the embedding, in a data object shown below:
class EntryWithEmbeddingItem
{
public Entry Entry { get; set; }
public IReadOnlyList<float> Embedding { get; set; }
public double SimilarityToBaseline { get; set; }
}
The code taking care of everything we just discussed is shown next. Additionally, once everything is done, the entries are sorted based on the descending similarity score. Note that the cosine similarity extension method - CosineSimilarity - comes from the newly installed Microsoft.SemanticKernel package.
var entriesWithEmbeddings = new List<EntryWithEmbeddingItem>();
foreach (var entry in feed.Entries)
{
var embedding = await client.GetEmbeddingsAsync(azureOpenAiDeploymentName,
new EmbeddingsOptions(entry.Title + Environment.NewLine + Environment.NewLine + entry.Summary));
var vector = embedding.Value.Data[0].Embedding.ToArray();
var similarity = vector.CosineSimilarity(baselineVector);
entriesWithEmbeddings.Add(new EntryWithEmbeddingItem
{
Embedding = embedding.Value.Data[0].Embedding.ToArray(),
SimilarityToBaseline = similarity,
Entry = entry
});
}
entriesWithEmbeddings = entriesWithEmbeddings.OrderByDescending(x => x.SimilarityToBaseline).ToList();
The final step is to display the results. In the previous blog post we used Spectre.Console to build a neat result table for the terminal. We will do the same here, and use all of the same techniques we already touched upon previously.
var table = new Table
{
Border = TableBorder.HeavyHead
};
table.AddColumn("Updated");
table.AddColumn("Title");
table.AddColumn("Authors");
table.AddColumn("Link");
table.AddColumn(new TableColumn("Similarity").Centered());
foreach (var entryWithEmbedding in entriesWithEmbeddings)
{
var color = entryWithEmbedding.SimilarityToBaseline switch
{
<= 0.75 => "red",
> 0.75 and <= 0.8 => "yellow",
_ => "green"
};
table.AddRow(
$"[{color}]{Markup.Escape(entryWithEmbedding.Entry.Updated.ToString("yyyy-MM-dd HH:mm:ss"))}[/]",
$"[{color}]{Markup.Escape(entryWithEmbedding.Entry.Title)}[/]",
$"[{color}]{Markup.Escape(string.Join(", ", entryWithEmbedding.Entry.Authors.Select(x => x.Name).ToArray()))}[/]",
$"[link={entryWithEmbedding.Entry.PdfLink} {color}]{entryWithEmbedding.Entry.PdfLink}[/]",
$"[{color}]{Markup.Escape(entryWithEmbedding.SimilarityToBaseline.ToString())}[/]"
);
}
AnsiConsole.Write(table);
The table will be color coded, where the entries with similarity score lower than 0.75 would be red, the ones with similarity score between 0.75 and 0.8 would be yellow, and the ones above 0.8 would be green.
And that’s it!
Trying it out 🔗
The only thing left to do is to try our application. Since Arxiv API tends to surface data with a delay, let us try a date from a week or so ago.
For example:
dotnet run 20230906
The output should be similar to:
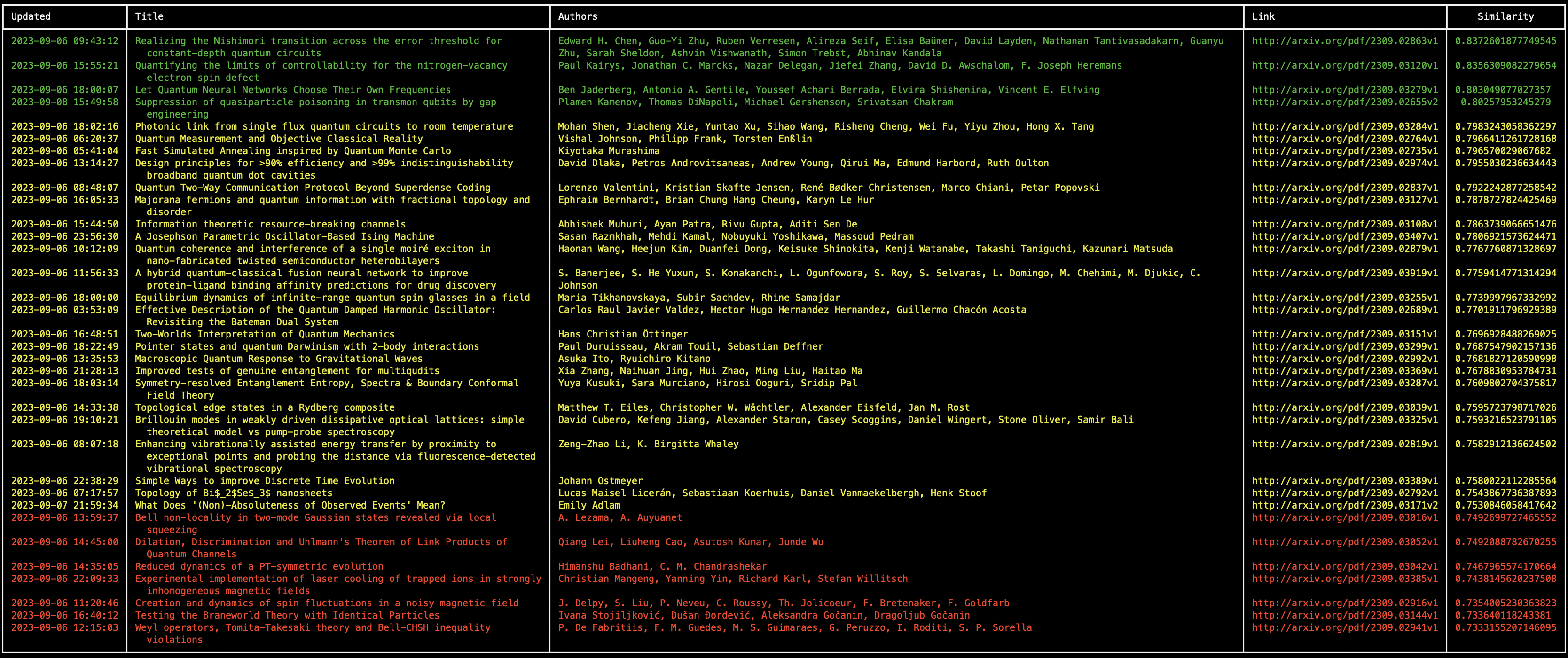
Of course the example is pretty basic, but the result is quite cool nonetheless! Hope this helps you get going - for example, as a next step it might make sense to save the embeddings into a vector database or index into a vector search, and query that, instead of computing them continuously on the fly.
All the source code for this article is available on Github.


