
In this post, we’ll explore a novel approach to optimizing AI workflows by strategically combining large language models (LLMs) with small language models (SLMs) using the “Minions pattern.” This technique, described in the research paper “Minions: Cost-efficient Collaboration Between On-device and Cloud Language Models” by Narayan et al., addresses one of the most pressing challenges in AI application development - the cost of processing large amounts of data with expensive, cloud-based language models. If you’ve ever built an AI system that needs to analyze extensive documents or datasets, you’ve probably felt the frustration of watching your API costs skyrocket as you process more and more content.
The Cost-Performance Dilemma 🔗
Modern AI applications often face a trade-off where powerful cloud-based LLMs like OpenAI’s GPT-series, Google’s Gemini or Anthropic’s Claude provide exceptional reasoning and synthesis capabilities, but they come with significant costs when processing large volumes of text. Consider a typical document analysis scenario where you need to extract specific information from extensive research papers or technical documents. Sending large amounts of text to premium LLMs can result in substantial token usage costs, and while individual responses might be fast, the expenses accumulate quickly across multiple queries and documents.
The Minions pattern takes a different approach by leveraging the complementary strengths of both LLMs and SLMs. Rather than treating model selection as an either-or decision, this pattern uses powerful cloud models for high-level reasoning and orchestration, while delegating the heavy lifting of data processing to efficient local models that can run on consumer hardware.
It’s a de-facto form of a hybrid agentic-AI system, where the “manager” LLM delegates tasks to “worker” SLMs, optimizing for both cost and performance.
How the Minions Pattern Works 🔗
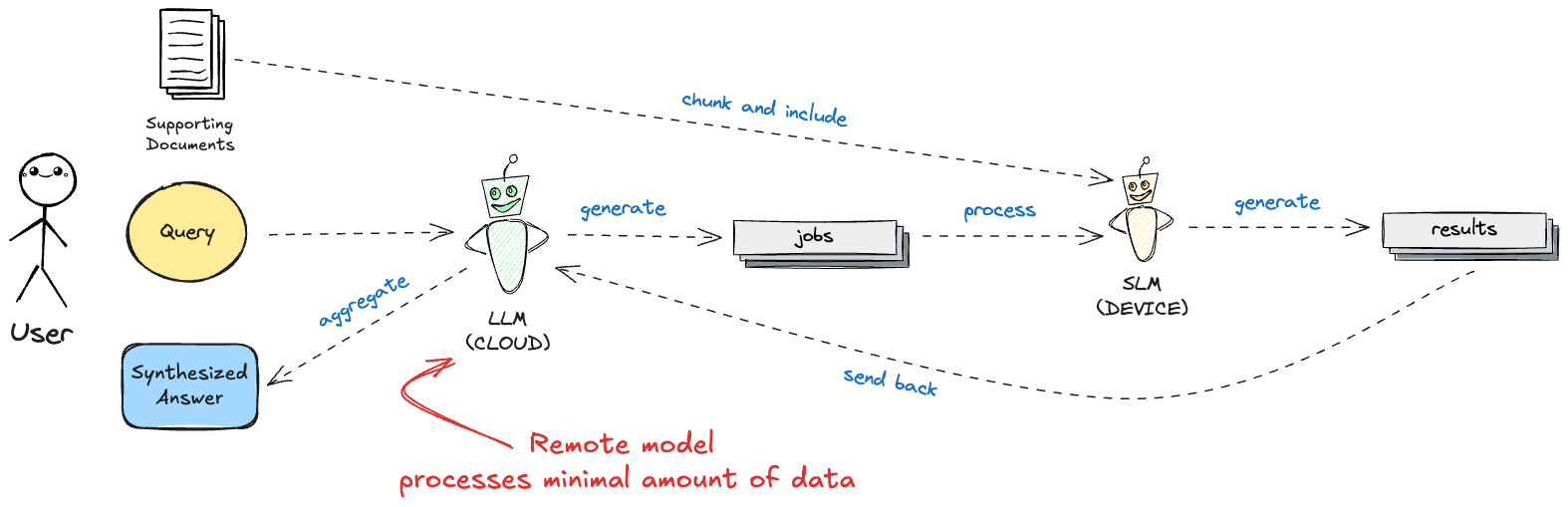
The Minions pattern consists of three distinct phases that create an efficient division of labor between expensive remote LLMs and cost-effective local SLMs. The workflow begins with job preparation, where the remote LLM analyzes the user’s complex query and breaks it down into simple, atomic extraction tasks that can be executed independently. This leverages the advanced reasoning capabilities of large models for what they do best - understanding complex requirements and decomposing them into actionable steps.
Next comes the phase of job(s) execution, where the local SLM processes document chunks using these well-defined tasks. The key insight here is that once we have simple, focused jobs, a smaller model can execute them just as effectively as a large one, but with lower computational costs. Each job is run against each document chunk, with the local model filtering and collecting only relevant results.
Finally, the workflow returns to the remote LLM for synthesis, where it aggregates the filtered results from local processing and synthesizes findings into a coherent final answer. This phase applies high-level reasoning and formatting capabilities that justify the cost of the premium model, while operating on a much smaller dataset than the original approach would require.
This approach transforms the typical “send everything to the expensive model” workflow into a collaborative process where the expensive model only handles the tasks that truly require its advanced capabilities. It also “offloads” the cost of processing from the cloud to the local device, where computation could be viewed as being effectively free (from the system standpoint).
Sample Implementation 🔗
Let’s implement this pattern using Azure OpenAI for our remote LLM and Apple’s MLX framework with Phi-4-mini for local processing. If you would learn more about Phi-4 and MLX, I previously blogged about them.
As our demonstration document, we’ll use a brief text about the early history of quantum mechanics. This example presents an interesting challenge, which may often arise in real-world use cases - the information we deal with, is well-known and likely exists in the training data of both local and remote models. Our goal here is to explicitly constrain the local model to extract information only from the provided text, effectively preventing both hallucinations and “correct” answers that might come from the model’s own knowledge rather than the source material.
Note: Because this example uses Python with MLX, an Apple Silicon Mac is required for local processing, but the same principles apply to other local inference frameworks.
The demo executes the Minions protocol in three main steps:
- The remote “manager” Azure OpenAI model creates jobs by generating code that is executed locally.
- The local “minion” Phi-4-mini model (running on-device via MLX) runs the jobs on document chunks and filters the results.
- The remote “manager” Azure OpenAI model receives the filtered results and provides the final answer.
Before diving into the code, a short disclaimer. This sample uses a relatively short document that wouldn’t normally require chunking. In real-world applications, you’d typically be processing multiple large documents, technical papers, or extensive datasets where chunking becomes necessary for memory and processing constraints - so our code includes chunking logic to illustrate how it would work in a more complex scenario.
First, let’s set up our dependencies and model configurations:
pip install mlx-lm openai python-dotenv
Now, let’s define our model access functions and core configuration:
from openai import AzureOpenAI
from mlx_lm.utils import load
from mlx_lm.generate import generate
from dotenv import load_dotenv
import json
import time
import os
load_dotenv()
LOCAL_MODEL_PATH = "mlx-community/Phi-4-mini-instruct-8bit"
def require_env(name: str) -> str:
val = os.getenv(name)
if not val:
raise RuntimeError(f"Missing required environment variable: {name}")
return val
AOI_MODEL_DEPLOYMENT = require_env("AZURE_OPENAI_DEPLOYMENT_NAME")
AOI_RESOURCE = require_env("AZURE_OPENAI_RESOURCE")
AOI_KEY = require_env("AZURE_OPENAI_KEY")
We are using an 8-bit quantized version of Phi-4-mini for local processing, which provides a good balance between performance and resource usage on consumer hardware. It’s an MLX-optimized model that can run efficiently on Apple Silicon Macs. Obviously this code already implies the following environment variables need to be set:
AZURE_OPENAI_DEPLOYMENT_NAME=your-deployment-name
AZURE_OPENAI_RESOURCE=your-resource-name
AZURE_OPENAI_KEY=your-api-key
Phase 1: Job Preparation with Remote LLM 🔗
The first phase uses our powerful remote LLM to analyze the user’s query and break it down into simple, atomic tasks. This is where we leverage the advanced reasoning capabilities of large models:
def prepare_jobs(user_query: str, use_predefined_jobs: bool = False) -> tuple[list, int]:
print("\n--- Step 1: Job Preparation (RemoteLM) ---")
print("RemoteLM is creating simple, targeted jobs based on the user query.")
if not use_predefined_jobs:
system_prompt = """You are a task decomposition expert. Your job is to break down a user's complex query into simple, atomic extraction tasks.
Rules:
- Each task should be a single, focused question that can be answered from a text chunk
- Tasks should be specific and actionable (e.g., "Find X and the year Y") and intended for finding information in the attached text
- Create 3-7 tasks depending on the complexity of the query
- Return ONLY a JSON array of task strings, nothing else
- Format: ["task 1", "task 2", "task 3"]"""
user_prompt = f"""User Query: {user_query}
Break this query down into simple extraction tasks. Return only the JSON array."""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = query_remote_lm(messages, temperature=0.3)
try:
response = response.strip()
if not response.startswith("["):
response = "[" + response + "]"
jobs = json.loads(response)
print(f"Jobs created: {jobs}")
return jobs, len(system_prompt) + len(user_prompt)
except json.JSONDecodeError as e:
print(f"Warning: Could not parse JSON response. Error: {e}")
print("Falling back to predefined jobs.")
# Fallback jobs for demonstration
jobs = [
"Find the contribution of Max Planck and the year it was made.",
"Find the contribution of Albert Einstein and the year it was made.",
"Find the contribution of Niels Bohr and the year it was made."
]
print(f"Using fallback jobs: {jobs}")
return jobs, 0
def query_remote_lm(messages: list, temperature: float = 0.1):
print("\n>>> Querying RemoteLM (Manager)...")
client = AzureOpenAI(
api_version="2024-06-01",
azure_endpoint=f"https://{AOI_RESOURCE}.openai.azure.com",
api_key=AOI_KEY,
)
start_time = time.time()
response = client.chat.completions.create(
model=AOI_MODEL_DEPLOYMENT,
messages=messages,
temperature=temperature,
max_tokens=500,
)
duration = time.time() - start_time
content = response.choices[0].message.content or ""
print(f"<<< RemoteLM Response received in {duration:.2f}s")
return content
Phase 2: Local Job Execution with SLM 🔗
This is where the magic happens - we use a small, efficient local Phi-4-mini to process large amounts of text. The key insight is that once we have simple, well-defined tasks, a smaller model can execute them just as effectively as a large one:
def execute_jobs_locally(document: str, jobs: list) -> tuple[list, int]:
print("\n--- Step 2: Job Execution (LocalLM) ---")
print(f"Loading local model from {LOCAL_MODEL_PATH}...")
local_model, tokenizer = load(LOCAL_MODEL_PATH)
chunk_size = 500
chunks = [document[i : i + chunk_size] for i in range(0, len(document), chunk_size)]
print(f"Document split into {len(chunks)} chunks.")
job_results = []
start_time = time.time()
total_chars_processed = 0
for i, chunk in enumerate(chunks):
for job in jobs:
prompt = LOCAL_MODEL_PROMPT_TEMPLATE_ROBUST.format(
chunk=chunk, job=job
)
response = run_local_inference(local_model, tokenizer, prompt)
total_chars_processed += len(chunk) + len(job)
if response.strip().lower() != "none":
print(f" - SUCCESS: Found relevant result in chunk {i + 1}!")
print(f" (LocalLM response: '{response}')")
job_results.append(response)
else:
print(f" - No relevant info found in chunk {i + 1}.")
print(f" (LocalLM response: '{response}')")
duration = time.time() - start_time
print(f"Local job execution finished in {duration:.2f}s.")
print(f"Filtered results to be sent to RemoteLM: {job_results}")
del local_model, tokenizer
return job_results, total_chars_processed
def run_local_inference(model, tokenizer, prompt: str) -> str:
messages = [{"role": "user", "content": prompt}]
if (
hasattr(tokenizer, "apply_chat_template")
and tokenizer.chat_template is not None
):
full_prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
else:
full_prompt = prompt
response = generate(
model, tokenizer, prompt=full_prompt, max_tokens=250, verbose=False
)
# Clean up response formatting
assistant_split_token = "<|assistant|>"
if assistant_split_token in response:
response = response.split(assistant_split_token)[-1]
end_split_token = "<|end|>"
if end_split_token in response:
response = response.split(end_split_token)[0]
return response.strip()
The critical component here is the prompt template used for local execution. It needs to be designed for reliability and consistency:
LOCAL_MODEL_PROMPT_TEMPLATE_ROBUST = """You are a meticulous and literal fact-checker. Your process is a strict two-step evaluation:
1. First, analyze the 'Context' to determine if it contains any information that can directly answer the 'Task'.
2. If the 'Context' is NOT relevant to the 'Task', you MUST immediately stop and respond with the single word: none.
- If and ONLY IF the information is present, extract the relevant facts verbatim or as a close paraphrase.
- Do NOT invent, guess, or mix information from different people or concepts. If the primary subject of the 'Task' (e.g., a person's name) is not mentioned in the 'Context', the answer is always 'none'.
- Your final output must be ONLY the extracted data or the word 'none'.
Context:
---
{chunk}
---
Task: Based ONLY on the text in the 'Context' above, {job}
"""
In my testing this is quite effective with Phi-4-mini, but it may require tweaking for other models. It is also possible that fine tuning the model on similar extraction may be necessary for more complex uses cases (or when using less capable local models).
Phase 3: Synthesis with Remote LLM 🔗
Finally, we use the remote LLM’s advanced capabilities to synthesize the filtered results into a coherent, well-structured answer:
def aggregate_and_synthesize(user_query: str, job_results: list) -> tuple[str, int]:
print("\n--- Step 3: Job Aggregation & Synthesis (RemoteLM) ---")
system_prompt = """You are a science historian. You have received a list of facts extracted from a document about the history of physics.
- Your task is to synthesize this information into a clear, structured answer to the user's original query.
- Organize the information by scientist.
- Do not mention the extraction process, just provide the final answer."""
results_str = "\n".join([f"- {res}" for res in job_results])
user_prompt = f"Original Query: {user_query}\n\nExtracted Information:\n{results_str}\n\nPlease provide a final, synthesized answer."
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
final_answer = query_remote_lm(messages)
return final_answer, len(system_prompt) + len(user_prompt)
Quality Evaluation 🔗
The demo includes an optional AI judge evaluation system that assesses the quality of the generated answers. This evaluation uses the same remote LLM to rate the final response on a scale of 1-5, considering factors like accuracy, completeness, clarity, and relevance.
The AI judge receives three key inputs: the user’s original query, the complete source document, and our generated answer. It then performs an evaluation comparing these elements to ensure the answer accurately reflects the source material and fully addresses the user’s question.
def evaluate_response_quality(
user_query: str, document: str, final_answer: str
) -> tuple[int, str]:
print("\n--- Step 4: Response Quality Evaluation (RemoteLM) ---")
print("RemoteLM is evaluating the quality of the generated answer...")
system_prompt = """You are an expert evaluator of AI-generated responses. Your task is to assess the quality of an answer given the original document, user query, and the generated response.
Please evaluate the response on a scale of 1-5 where:
1 = Very Poor (completely inaccurate or irrelevant)
2 = Poor (mostly inaccurate with some relevant information)
3 = Fair (some accuracy but missing key information or has notable errors)
4 = Good (mostly accurate and complete with minor issues)
5 = Excellent (highly accurate, complete, and well-structured)
Consider these criteria:
- Accuracy: Does the answer correctly reflect the information in the source document?
- Completeness: Does it address all parts of the user's query?
- Clarity: Is the answer well-organized and easy to understand?
- Relevance: Does it stay focused on what was asked?
Provide your evaluation in this exact format:
Score: [1-5]
Reasoning: [Brief explanation of your assessment]"""
user_prompt = f"""Original Document:
{document}
User Query: {user_query}
Generated Answer:
{final_answer}
Please evaluate this response."""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
evaluation_response = query_remote_lm(messages, temperature=0.3)
# Extract score from response
try:
score_line = [
line for line in evaluation_response.split("\n")
if line.startswith("Score:")
][0]
score = int(score_line.split(":")[1].strip())
except (IndexError, ValueError):
score = 0 # Default if parsing fails
return score, evaluation_response
Running the demo 🔗
With all the code in place, we are ready to run the complete Minions workflow. The main function orchestrates all three phases and provides performance metrics. The “demo” user query asks about the contributions of Planck, Einstein, and Bohr to quantum mechanics.
def main():
start_time = time.time()
print("=" * 50)
print(" MINIONS Protocol Demo (Quantum Mechanics)")
print("=" * 50)
# User query
user_query = "what did Planck, Einstein, and Bohr contribute to quantum mechanics?"
print(f"\nUser Query: {user_query}")
# Phase 1: Job preparation
jobs, prep_job_chars = prepare_jobs(user_query)
# Phase 2: Local execution
results, local_chars_processed = execute_jobs_locally(QUANTUM_MECHANICS_HISTORY, jobs)
if not results:
print("\nLocalLM could not find any relevant information. Halting.")
return
# Phase 3: Synthesis
final_answer, aggregate_chars = aggregate_and_synthesize(user_query, results)
# Optional: Evaluate the response quality
evaluation_score, evaluation_details = evaluate_response_quality(
user_query, QUANTUM_MECHANICS_HISTORY, final_answer
)
total_duration = time.time() - start_time
print("\n--- FINAL ANSWER ---")
print(final_answer)
print("=" * 50)
print("\n--- RESPONSE QUALITY EVALUATION ---")
print(f"Quality Score: {evaluation_score}/5")
print(f"Evaluation Details:\n{evaluation_details}")
print("=" * 50)
remote_chars_sent = prep_job_chars + aggregate_chars
print("\n--- Performance & Results Report ---")
print(f"Total Workflow Duration: {total_duration:.2f}s")
print("\nCost & Efficiency Analysis (using character counts):")
print(f" - Characters processed by FREE LocalLM: ~{local_chars_processed}")
print(f" - Characters sent to EXPENSIVE RemoteLM API: ~{remote_chars_sent}")
print("\nAnswer Quality:")
print(f" - AI Judge Score: {evaluation_score}/5")
print("=" * 50)
if __name__ == "__main__":
main()
Running this with python demo.py produces the following output:
==================================================
MINIONS Protocol Demo (Quantum Mechanics)
==================================================
User Query: what did Planck, Einstein, and Bohr contribute to quantum mechanics?
--- Step 1: Job Preparation (RemoteLM) ---
RemoteLM is creating simple, targeted jobs based on the user query.
>>> Querying RemoteLM (Manager)...
<<< RemoteLM Response received in 1.08s
Jobs created: ["Find Planck's contributions to quantum mechanics", "Find Einstein's contributions to quantum mechanics", "Find Bohr's contributions to quantum mechanics"]
--- Step 2: Job Execution (LocalLM) ---
Loading local model from mlx-community/Phi-4-mini-instruct-8bit...
Document split into 6 chunks.
- SUCCESS: Found relevant result in chunk 1!
(LocalLM response: 'Max Planck's 1900 quantum hypothesis that any energy-radiating atomic system can theoretically be divided into a number of discrete "energy elements" (quanta).')
- SUCCESS: Found relevant result in chunk 1!
(LocalLM response: 'Albert Einstein in 1905 proposed the photoelectric effect, which further contributed to the development of quantum mechanics.')
- SUCCESS: Found relevant result in chunk 2!
(LocalLM response: 'Niels Bohr proposed a new model for the atom in 1913, where electrons travel in discrete, quantized orbits around the nucleus.')
- SUCCESS: Found relevant result in chunk 3!
(LocalLM response: 'Bohr's model successfully explained the spectral lines of the hydrogen atom.')
Local job execution finished in 34.23s.
--- Step 3: Job Aggregation & Synthesis (RemoteLM) ---
>>> Querying RemoteLM (Manager)...
<<< RemoteLM Response received in 2.75s
--- FINAL ANSWER ---
Max Planck, Albert Einstein, and Niels Bohr each made foundational contributions to the development of quantum mechanics:
- Max Planck (1900) introduced the quantum hypothesis, proposing that energy emitted by atomic systems is quantized and can be divided into discrete units called "energy elements" or quanta. This idea laid the groundwork for the concept of quantization in physics.
- Albert Einstein (1905) extended Planck's concept by explaining the photoelectric effect, demonstrating that light itself is quantized into particles called photons. This work provided critical evidence for the quantum nature of light and helped establish quantum theory.
- Niels Bohr (1913) developed a new atomic model in which electrons orbit the nucleus in specific, quantized energy levels or orbits. Bohr's model successfully explained the discrete spectral lines observed in the hydrogen atom, further validating the quantum approach to atomic structure.
Together, these contributions formed key pillars of early quantum mechanics, shaping our understanding of energy quantization, the particle nature of light, and atomic structure.
==================================================
--- Performance & Results Report ---
Total Workflow Duration: 42.98s
Cost & Efficiency Analysis (using character counts):
- Characters processed by FREE LocalLM: ~23,079
- Characters sent to EXPENSIVE RemoteLM API: ~1,688
Answer Quality:
- AI Judge Score: 5/5
==================================================
As we can see from the output, the Minions pattern effectively reduces the number of characters sent to the expensive remote LLM while still producing a high-quality answer. The AI judge rated the final response a perfect 5 out of 5, indicating that the synthesis was accurate, complete, and well-structured.
In our test run, the local model handled the vast majority of character processing while the remote LLM focused on the high-value tasks of job decomposition and synthesis. While the local processing took longer than a direct cloud API call would have (about 34 seconds compared to what might be 3-5 seconds for a single API call), the cost savings would be substantial.
Final Thoughts 🔗
The real value of this pattern becomes apparent when you consider scaling scenarios. While a single document analysis might complete faster with a direct API call, processing hundreds of documents or implementing this in a system with high query volumes reveals the economic advantages. The pattern essentially converts what would be a linear cost scaling problem (more documents = proportionally more API costs) into one where the expensive operations remain constant regardless of document volume, though with longer processing times due to local inference.
The results demonstrate several key advantages of the Minions pattern:
- Cost optimization occurs naturally as the local model processes the bulk of the textual data, dramatically reducing API costs compared to sending everything through premium services, though with longer processing times.
- Quality preservation remains strong because the remote LLM still handles the complex reasoning tasks that justify its expense.
- Scalability improves since processing costs scale primarily with local computation rather than expensive API calls, and reliability benefits from the pattern’s natural filtering mechanism, which ensures only relevant information reaches the final synthesis stage.
However, it is not a one-size-fits all solution. The pattern works best for extraction and analysis tasks that can be decomposed into simple, independent jobs. Complex reasoning tasks that require maintaining context across large text spans may not benefit as much from this approach. Quality control becomes critical as well, since the effectiveness depends heavily on the quality of job decomposition and the local model’s ability to execute simple tasks reliably. Poor job design can lead to missed information or false positives that propagate through the entire workflow.
The complete code for this example is available in a - surprise, surprise - GitHub repository.


